




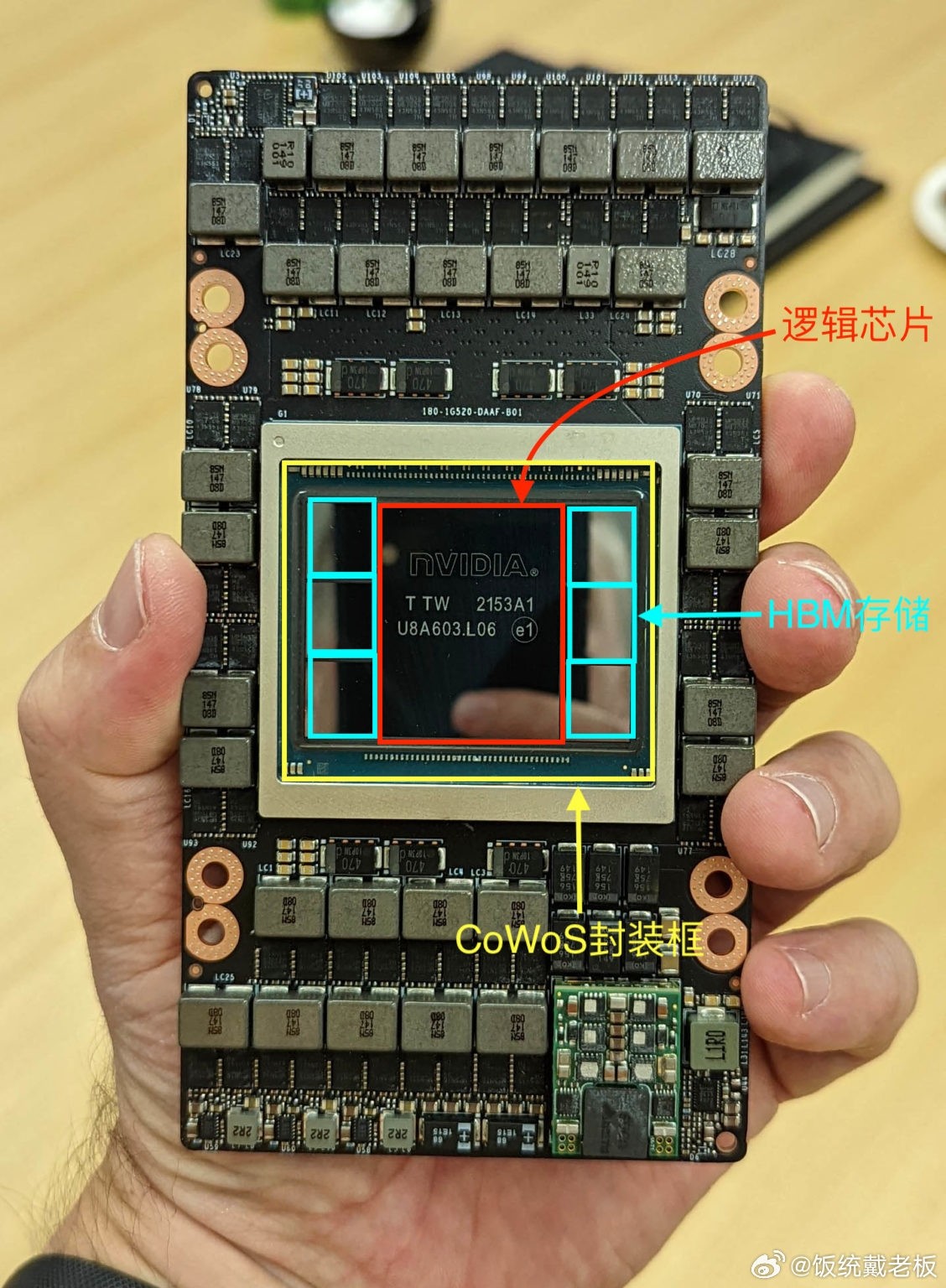
美国当地时间11月14日,在达拉斯举行的全球超算大会SC18上,浪潮发布集成HBM2高速缓存的FPGA AI加速卡F37X,可在不到75W典型应用功耗提供28.1TOPS的INT8计算性能和460GB/凯云官网s的超高数据带宽,实现高性能、高带宽、低延迟、低功耗的AI计算加速。
F37X是浪潮专为AI极致性能设计的尖端FPGA加速卡。它采用Xilinx Virtex UltraScale+架构,INT8计算性能达到了28.1TOPS,集成8GB HBM2高速缓存,带宽达460GB/s。F37X典型应用功耗仅为75瓦,性能功耗比高达375Gops/W。性能数据显示,浪潮F37X在AI图像识别实时推理场景,基于GoogLeNet深度学习网络模型,当BatchSize=1时性能高达8600 images/s,是CPU性能的40倍。同时F37X可支持SDAccel 开发环境与C/C++、OpenCL和RTL三种主流的编程语言,覆盖机器学习推理、视频图像处理、数据库分析、金融、安全等典型AI应用领域,提供强大的生态支持,具备更加出色的易编程性,可灵活快速开发和迁移不同的AI定制算法应用,在软件生产力上实现了质的飞跃。
Xilinx数据中心销售副总裁Freddy Engineer表示,Xilinx的U200、U250 FPGA卡已经在浪潮NF5280M5、NF5468M5、GX4等多款AI服务器上进行了认证和测试,不同型号的服务器在板卡支持密度、互联设计等方面有不同的创新考虑,可以适用于视频转码、图像识别、语音识别、自然语言处理、基因组测序分析、NFV、大数据分析查询等各类应用场景。
浪潮高级技术总监郭洪昌表示:Xilinx是全球领先的FPGA、可编程SoC 与 ACAP解决方案提供商,浪潮一直致力于创新FPGA软硬件技术,双方在推动FPGA技术应用、加速AI计算等方面有着广泛的共识。浪潮将与Xilinx 围绕客户需求加强FPGA技术合作与创新,为全球FPGA、AI用户带来极致的计算加速体验。
浪潮是全球领先的AI计算力专业厂商,从计算平台、管理套件、框架优化、应用加速等四个层次致力于打造敏捷、高效、优化的AI基础设施。据IDC《2017年中国AI基础架构市场调查报告》显示,浪潮AI服务器市场份额达57%高居第一。同时,浪潮致力于通过创新设计为世界范围的客户提供领先的计算设备,目前已成为全球多家领先公司的合作伙伴。
这几天一直在Google Cloud Next 2026,除了Keynote之外,其实很重要的一个行动,就是去各种Session听讲,去展区观光,以及和不同行业、不同地区的开发者聊天。因为在这个AI技术变革的时代,确实有很多问题失去了标准答案,所以需要听听更多人的意见,见贤思齐。
这项由香港大学、上海人工智能实验室、上海交通大学和香港中文大学联合开展的研究提出了HiVLA框架,通过将机器人操控系统拆分为高层视觉语言规划和低层扩散变换器执行两个模块,解决了端到端VLA模型在精细操控任务中推理能力和动作精度互相拖累的核心矛盾。系统利用视觉语言模型生成边界框,提取高清局部目标特写,并通过级联交叉注意力机制将全局场景、局部细节和子任务语义融合注入执行模型,在RoboTwin仿真平台上比现有最强基线个百分点,在真实物理机器人实验中同样展现出显著优势。
微软首次在其51年历史中推出自愿退休买断计划。根据内部备忘录,员工工龄与年龄之和达到70即可申请。此举旨在以较温和的方式缩减员工规模,避免大规模裁员。微软美国员工约12.5万人,此次计划覆盖约7%,即约8750名员工。近年来微软已历经多轮裁员,去年夏季曾削减9000个岗位。
这项由英国剑桥MediaTek Research团队完成的研究(arXiv:2604.07466v2,2026年4月)提出了一种名为字节级蒸馏(BLD)的方法,用于解决AI语言模型之间因分词方案不同而无法直接传递知识的难题。该方法将老师模型的输出概率转换为字节级概率,并为学生模型临时安装轻量级字节级解码头,通过这一所有模型共有的底层接口完成知识传递。实验覆盖1B至8B参数规模的模型,在多个基准上与现有复杂方法持平甚至超越,但跨分词器蒸馏整体仍是开放难题。


